脉冲神经网络背景
神经网络进化
到目前为止,神经网络的进化之路,可以化为如下三个阶段:
- 第一代人工智能:感知器,一个简单的神经元只能处理二进制数据。
- 第二代神经网络:通常是全连接的神经网络,它们输入连续的值,然后输出连续的值 ,也就是目前我们一直在使用各种神经网络,BP,CNN,RNN等,本质来讲,这些神经网络都是基于神经脉冲的频率进行编码( rate coded)。
- 第三代神经网络:脉冲神经网络(spiking neural networks),其模拟神经元更加接近实际,把时间信息的影响也考虑其中 。旨在弥合神经科学与机器学习之间的鸿沟,使用接近真实的生物神经模型来进行计算。SNN可以归类为类脑计算,是认为生物智能是人工智能想要达到的目标和方向,标榜自然智进行改进与深化。
理论上我们现在的神经网络已经从连续的输出转变为了二元输出,表面看起来退化了。然而,脉冲训练给了我们更强大的处理 时空数据 的能力,而这些时空数据通常就是我们的真实世界的感官数据。
- 空间:神经元只与其本地的神经元相连接,可以分别处理输入块的输入(类似于CNN使用过滤器一样)
- 时间:脉冲训练是随着时间发生的,因此我们损失了二进制编码,但是获得了脉冲发生时间相关的信息
这使得可以非常自然的处理时间相关的数据而不需要引入RNN而带来复杂性。
人们可以精确的建立基于脉冲产生时间神经网络模型。这种新型的神经网络采用脉冲编码(spike coding),通过获得脉冲发生的精确时间,这种新型的神经网络可以进行获得更多的信息和更强的计算能力。 实际上已经证明,脉冲神经元从根本上来讲,是比传统的人工神经元更为强大的计算单元。
脉冲神经网络的诞生的原因
- 人工神经网络需要高性能的计算平台。
- 人工神经网络仍不能实现强人工智能,人们认为是因为其与生物大脑仍存在巨大差距。
SNN vs ANN
比较
- SNN与ANN最主要的不同就是使用离散的脉冲信号替代ANN网络中传播的连续的模拟信号。SNN的网络结构与ANN类似,主要使用类似于全连接网络或者CNN结构的网络。为了在这种网络结构上产生脉冲信号,SNN使用了更加复杂也更加贴近于生物的神经元模型,目前使用最多的是Integrity-Fire(IF)模型和Leaky integrity-Fire(LIF)模型。对于这类神经元模型来说,输入信号直接影响的是神经元的状态(膜电位),只有当膜电位上升到阈值电位时,才会产生输出脉冲信号。
- 脉冲是在时间点上发生的离散的事件,而不是连续的值。当一个神经元被激活,它会产生一个信号传递给其他神经元,提高或降低其膜电位。(自然生物神经网络的“神经递质”),然后该神经元的值会被重置。SNN通常是稀疏连接的,并且通过特殊的网络拓扑结构来实现。
- 传统的人工神经元模型主要包含两个功能,一是对前一层神经元传递的信号计算加权和,二是采用一个非线性激活函数输出信号。 前者用于模仿生物神经元之间传递信息的方式,后者用来提高神经网络的非线性计算能力。
- 相比于人工神经元,脉冲神经元则从神经科学的角度出发,对真实的生物神经元进行建模。脉冲神经网络,其模拟神经元更加接近生物实际。
- 脉冲神经元存在源于生物神经网络中神经元的侧向抑制作用。所谓侧向抑制,就是指处于同一层中的不同神经元之间的相互作用。当一个神经元接受刺激被激活以后,它除了将刺激传递到下一层神经元,还会因为本身被激活而抑制其同一层内周边神经元被激活的概率。从神经元模型中体现的就是膜电位高于静息电位(-65mV或者是其他预设值)的神经元会抑制其周围甚至同层内所有神经元的膜电位增长。这种侧向抑制作用使得受到刺激较多的神经元比其他神经元有更大概率产生脉冲信号输出,从ANN的角度来看,这有点类似于Attention机制,但是又比Attention机制更加强烈和粗暴。 如下图,最右一层的黄色神经元对蓝色神经元的影响

SNN的特点:
- 采用了生物神经元模型如IF,LIF等,比之前ANNs的神经元更接近生物。
- 信息的传递是基于脉冲进行。所以网络的输入要进行额外编码,例如频率编码和时间编码等,转现在的数据(例如图片的像素)转换成脉冲
- 基于脉冲的编码,能蕴含更多的信息
神经元模型特点:
- 神经元的输入输出信号形式与ANN不同
- 脉冲神经元不需要额外的激活函数
- 脉冲神经元不需要输入偏置(bias)
很多工作便是基于神经元模型开展
脉冲神经元模型

神经元动力学可以被设想为一个总和过程(有时也称为“集成”过程),并结合一种触发动作电位高于临界电压的机制。 一般来所,Vrest<Vth,当Vi(t)(对所有所输入求和后的所得到电压)上升到阈值θ时就会引起动作电位从而产生脉冲。发放的脉冲的形状是相似的,其传递的信息实质在于某时刻脉冲的有无。
动作电位被称为事件(忽视脉冲的形状)的神经元模型被称为IF模型。对于描述IF模型,我们需要两样东西:
1.膜电位Vi(t)的公式
2.产生脉冲的机制
IF模型
硬件模型:IF模型只有一个电容,没有并联的电阻,因为电阻实际等效于泄露电流,对应LIF模型。 高通低阻
$$\frac{d V}{d t}=\frac{1}{C} I(t)$$
模型过于简单
Hodgkin-Huxley( HH)模型
完全仿生物神经元模型
HH模型是一组描述神经元细胞膜的电生理现象的非线性微分方程,直接反映了细胞膜上离子通道的开闭情况。
HH模型所对应的电路图如图所示,其中 C 代表脂质双层(lipid bilayer) 的电容;RNa, RK, Rl分别代表钠离子通道、 钾离子通道与漏电通道的电阻(RNa, RK 上的斜箭头表明其为随时间变化的变量, 而 R l 则为一个常数); E l, E Na, E K 分别代表由于膜内外电离子浓度差别所导致的漏电平衡电压、钠离子平衡电压、钾离子平衡电压;膜电压V代表神经膜内外的电压差,可以通过HH模型的仿真来得到V随时间变化的曲线。

神经元的膜电压变化,如图所示。
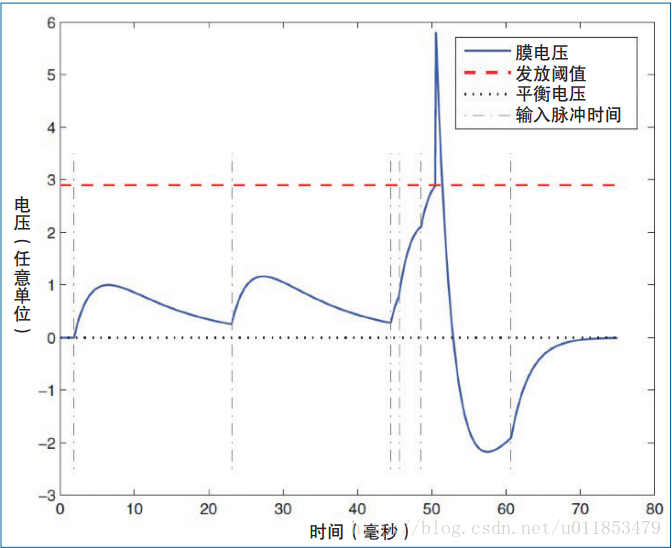
图中共有6个输入脉冲(垂直虚线所示),每个脉冲触发膜电压V的快速上升。如果输入脉冲之间的时间间隔较长(例如在1ms与22ms到达的2个脉冲之间,由于漏电通道的作用,没有新的输入脉冲),膜电压V就会随着时间逐渐降低至平衡电压El。如果有多个输入脉冲在短时间内连续到达(例如在45~50ms 之间的3 个脉冲),那么膜电压V会上升至发放阈值Vth(红色水平虚线所示) 而触发一个输出脉冲。之后V被重置为低于平衡电压El的Vreset,然后逐渐回升至平衡电压El。神经元的行为与输入的时间特性密切相关,一组脉冲如果在短时间内连续到达,可以触发神经元的脉冲;但是同样数量的一组脉冲如果在较长时间内分散到达,那么膜电压的漏电效应便不会产生脉冲。
HH模型精确地描绘出膜电压的生物特性,能够很好地与生物神经元的电生理实验结果相吻合,但是运算量较高,难以实现大规模神经网络的实时仿真。
Leaky Integrate and Fire(LIF)模型

为了解决HH模型运算量的问题,许多学者提出了一系列的简化模型。LIF模型将细胞膜的电特性看成电阻和电容的组合。 leaky表示泄露,由于细胞膜是不断进行膜内外离子的交换,所以当只有一次输入时,电压会自动发生泄漏逐渐回落到静息状态。对于LIF模型一般是认为先下降低于Vrest,再上升的静息电位处,而IF神经元一般是认为直接回落到静息状态处,这里涉及到一个reset电位。这里的reset可以看成输入一个短暂的电流脉冲
$$I_r=-q_r \sum_f \delta\left(t-t^{(f)}\right)=-C\left(\vartheta-u_r\right) S(t)$$
其中$q_{r}=C\left(\vartheta-u_r\right)$为电容需要移除的电荷量,因为这是模电压直接由电容器的电压设定。
响应公式
$r(j)=\left\{\begin{array}{ll}{\left[\tau _{r e f}-\tau _{R C} \log \left(1-\frac{V_{t h}}{j}\right)\right]^{-1}} & {\text { if } j>V_{t h}} \\ {0} & {\text { otherwise }}\end{array}\right.$r(j)为firing rate,j为膜电压

虚线为真实,一般用实线替代,Ur为重置电压
缺点:
LIF模型是高度简化的,同时忽略了很多的有关神经动力学的内容。
- 输入(input),在该模型中输入是突触前神经元或注入电流的线性叠加,并独立于后突触神经元。
- 每次激活后直接reset,不能保留前一脉冲。
Izhikevich模型
HH模型精确度高,但运算量大。LIF模型运算量小,但牺牲了精确度。Izhikevich模型结合了两者的优势,生物精确性接近HH模型,运算复杂度接近LIF模型。
脉冲编码方式
现在主流的认为神经元的编码方式有两种:
1、速率编码(rate code)
最早的编码是mean firing rate,计算在一段时间内脉冲数的平均值,由于采用了均值,所以很多细节信息不能获取。

如上图所示,计算在TT的时间内的mean firing rate,右图为发放率随输入电流的曲线图。
- 在运动细胞中,支配肌肉的力量完全取决于“脉冲发放率”,可以简单理解成单位时间的脉冲发放数量。使用速率编码时,认为信息是包含在脉冲的发放频率当中。当使用脉冲编码,我们关注的对象就应该是脉冲发放率,而不是特定的脉冲序列。 脉冲的发放频率有两个解读方法:1、统计。2、概率。
- 事实上,至少有三种不同的速率概念,经常被混淆和同时使用。无论是随时间推移的平均数,还是实验的几次重复的平均值,或者是神经元群体的平均值。
- 当采用速率编码时,任何可能编码在脉冲序列中精确信息都会被忽略。即采用速率编码就会自动丢失准确时间编码的信息。
- 频率编码的效率不高,但具有很强的抗噪声能力。
- 许多研究发现,神经编码的时间分辨率是毫秒级的,这表明精准时间编码在神经元编码中存在,而且十分重要。在视网膜,外侧膝状核(LGN)和视皮层以及许多其他感觉系统中,观察到神经元在毫秒尺度上精确地对刺激作出反应。这个发现有力的支持时间编码的方式。
2、时间编码(temporal code):是基于单个脉冲的精准时间,可以理解成他们时刻关注着外部的刺激,一般该种细胞存在在听觉系统或听觉回路中。 采用基于时间编码,可以更高效的信息进行表示,同时速度更快(例如神经元可以对特定位置的脉冲作出响应)temporal code编码方式细分有几种:
- latency code:延迟码是一种特定形式的时间编码,即编码信息在时间上相对于编码窗口长度,这通常是与刺激的发生时间有关。
- interspike intervals code :这种编码是通过两个脉冲之间的相对时间来表示编码信息。
- phase of fireing code
- 相比速率编码,采用时间编码能携带更多的信息,同时具有更强的生物真实性和计算效率。
- 基于精确时间编码的学习算法:spike-time-dependent plasticity(STDP),Tempotron rule,SpikeProp rule ,SPAN rule, Chronotron rule ,ReSuMe relu
另外的划分方式:
rate-based
ANN传统网络,输出的数值可看成rate,在转换中我们实质需要的权重,训练得到权重值得范围取决了转换成SNN的损失情况。
spike-based
SNN是以脉冲传输信息的,以上面的rate code进行编码绘图可得出上面ANN激活后对应的图,实质上不论事用rate code 或 spike code 其本质都是一样,在实际中在SNN用何种编码是由模拟器底层实现,不论用何种编码都能将ANN权重应用到SNN
event-driven或event-based
SNN运行平台由来自神经形态传感器或将图片转换成脉冲的输入,创建稀疏,无帧和精确定时的事件流,模型LIF和IF,我们把每个脉冲的产生看成一个事件,所以说SNN是以事件驱动的,事件驱动的神经元系统将其计算工作集中在网络的当前活动部分,由于输入是一连串的脉冲,所以可以看成整个网络的神经元都在进行工作,但他们只关注其自己当前所接受的东西,所以相对于ANN他是低延迟
frame-based
对于ANN传统网络而言,与上述event-driven对比,ANN是在二进制计算机上运行,每次传输都是一个实际的数值,对于训练的一张图片而言,其每个像素都是一个实际值,然后逐层的通过网络,当通过第一层时,后面层的神经元不工作,当通过到第三层时,第一二层和后面的层都不工作,所以延迟高。
SNN的局限
理论上SNN比第二代人工神经网络更为强大,却没有被广泛使用,主要问题:
- SNN目前的主要问题在于 如何训练。尽管我们有无监督的生物学习方法,比如Hebbian和STDP,但是还没有找到比第二代生成网络更为高效的有监督的SNN训练方法。由于脉冲训练是不可微分的,我们不能在SNN训练中使用梯度下降而不丢失脉冲的精确时间信息。因此,为了使得SNN能够应用于现实世界的任务,我们需要开发一个有效的监督学习方法。这是一个非常难的任务,因为我们需要了解人类大脑如何真正的进行学习,从而给定这些网络生物的现实性。
- 另外问题是在通用硬件上模拟SNN是非常的计算密集型的,因为它需要模拟不同的微分方程。但是类似于IBM的TrueNorth等模拟神经元的硬件通过特殊的模拟神经元的硬件可以来解决这个问题,它可以利用神经元脉冲的离散和稀疏的特性。
脉冲神经网络
脉冲神经网络的拓扑结构
同传统的人工神经网络一样,脉冲神经网络同样分为三种拓扑结构。它们分别是前馈型脉冲神经网络(feed-forward spiking neural network)、递归型脉冲神经网络(recurrent spiking neural network)和混合型脉冲神经网络(hybird spiking neural network)。
1. 前馈型脉冲神经网络
在多层前馈脉冲神经网络结构中,网络中的神经元是分层排列的,输入层各神经元的脉冲序列表示对具体问题输入数据的编码,并将其输入脉冲神经网络的下一层。最后一层为输出层,该层各神经元输出的脉冲序列构成网络的输出。输入层和输出层之间可以有一个或者多个隐藏层。
此外,在传统的前馈人工神经网络中,两个神经元之间仅有一个突触连接,而脉冲神经网络可采用多突触连接的网络结构,两个神经元之间可以有多个突触连接,每个突触具有不同的延时和可修改的连接权值。多突触的不同延时使得突触前神经元输入的脉冲能够在更长的时间范围对突触后神经元的脉冲发放产生影响。突触前神经元传递的多个脉冲再根据突触权值的大小产生不同的突触后电位。
2. 递归型脉冲神经网络
递归型神经网络不同于多层前馈神经网络和单层神经网络,网络结构中具有反馈回路,即网络中神经元的输出是以前时间步长上神经元输出的递归函数。递归神经网络可以模拟时间序列,用来完成控制、预测等任务,其反馈机制一方面使得它们能够表现更为复杂的时变系统;另一方面也使得有效学习算法的设计及其收敛性分析更为困难。传统递归人工神经网络的两种经典学习算法分别为实时递归学习(real-time recurrent learning)算法和随时间演化的反向传播(backpropagation through time)算法,这两种算法都是递归地计算梯度的学习算法。
递归脉冲神经网络是指网络中具有反馈回路的脉冲神经网络,由于其信息编码及反馈机制不同于传统递归人工神经网络,由此网络的学习算法构建及动力学分析较为困难。递归脉冲神经网络可应用于诸多复杂问题的求解中,如语言建模、手写数字识别以及语音识别等。递归脉冲神经网络可分为两大类:全局递归脉冲神经网络(fully recurrent spiking neural network);另一类是局部脉冲神经网络(locally recurrent spiking neural network)。
3. 混合型脉冲神经网络
混合型脉冲神经网络即包括前馈型结构,又包含递归型结构。
信息的脉冲序列编码方法
从神经科学的角度来看,第二代人工神经网络是一种基于“发放频率”的神经元计算方式。随着研究的深入,神经科学家指出生物神经系统采用神经元的脉冲时序来编码信息,而不仅仅是用神经元脉冲的“发放频率”来编码信息。实际上,神经元的脉冲发放频率不能完全捕获脉冲序列中包含的信息。例如,已经发现初级听觉皮层神经元群体能在短时间内通过分组相邻脉冲来协调动作电位的相对时间,并没有改变每秒发放的脉冲数量,这样,神经元甚至可以在平均发放频率没有改变的情况下给出特定的刺激信号。
更具有生物可解释性的脉冲神经网络,采用精确定时的脉冲序列来编码神经信息。神经网络内部的信息传递是由脉冲序列完成的,脉冲序列是由离散的脉冲时间点组成的时间序列,因此,在进行脉冲神经网络的模拟与计算时,包含以下步骤:①当输入数据或神经元受到外界刺激时,经过特定的脉冲序列编码方法,可将数据或外界刺激编码成特定的脉冲序列;②脉冲序列在神经元之间传递并经过一定的处理,处理之后将输出的脉冲序列通过特定的解码方法进行解码并给出具体的响应。
对于神经信息的脉冲序列编码问题,借鉴生物神经元的信息编码机制,研究者提出了许多脉冲神经网络的脉冲序列编码方法。例如,首脉冲触发时间编码方法、延迟相位编码方法、群体编码方法等。
脉冲神经网络的学习算法
人工神经网络主要基于误差反向传播(BP)原理进行有监督的训练,目前取得很好的效果。对于脉冲神经网络而言,神经信息以脉冲序列的方式存储,神经元内部状态变量及误差函数不再满足连续可微的性质,因此传统的人工神经网络学习算法不能直接应用于脉冲神经神经网络。
基于脉冲时间层次的学习方法研究,对于通过理论模型来验证生物神经系统的信息处理和学习机制是必须的。通过生物可解释的方式建立人工神经系统,科学家希望可以通过神经科学和行为实验来达到预期目的。大脑中的学习可以理解为突触连接强度随时间的变化过程,这种能力称为突触可塑性(synaptic plasticity)。
脉冲神经网络的学习方式主要包括无监督学习(unsupervised learning)、监督学习(supervised learning)和强化学习(reinforcement learning)等。
1. 无监督学习算法
脉冲神经网络的无监督学习算法大多是借鉴传统人工神经网络的无监督学习算法,是在Hebb学习规则不同变体的基础上提出的。神经科学的研究成果表明,生物神经系统中的脉冲序列不仅可引起神经突触的持续变化,并且满足脉冲时间依赖可塑性(spike timing-dependent plasticity,STDP)机制。在决定性时间窗口内,根据突触前神经元和突触后神经元发放的脉冲序列的相对时序关系,应用STDP学习规则可以对突触权值进行无监督方式的调整。
STDP是一种非常经典的模拟生物的神经网络优化方法。STDP认为在一个事件中,对于相邻的位于前后两层的两个都产生了神经冲动的神经元,如果前一个神经元先产生脉冲,那么随着两个脉冲之间的时间间隔的减小,两个神经元之间突触连接的可能性逐渐增大。反之,如果前一个神经元后产生脉冲,则随着两个脉冲之间的时间间隔的减小,两个神经元之间突触连接的可能性逐渐减小。应用在SNN中,这里的突触连接可能性可以转变为突触连接强度。
这算法从生物可解释性出发,主要基于赫布法则 (Hebbian Rule)。Hebb在关于神经元间形成突触的理论中提到,当两个在位置上临近的神经元,在放电时间上也临近的话,他们之间很有可能形成突触。而突触前膜和突触后膜的一对神经元的放电活动(spike train)会进一步影响二者间突触的强度。这个假说也得到了实验验证。华裔科学家蒲慕明和毕国强在大树海马区神经元上,通过改变突触前膜神经元和突触后膜神经元放电的时间差,来检验二者之间突触强度的变化。实验结果如图所示。
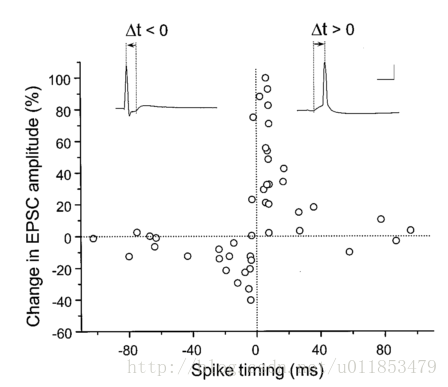
其中,EPSC表示突触强度。当EPSP(兴奋性脉冲)在spike之前产生,突触强度增强。当EPSP在spike之后产生,突触强度减弱。这个现象被称为脉冲序列相关的可塑性(Spike Timing Dependent Plasticity,STDP)。
基于该生物现象,提出了两种主流的无监督STDP学习算法。
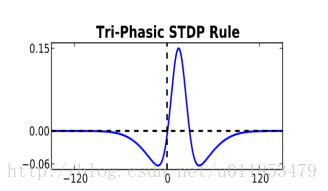
三相STDP
权值更新规则如公式所示。
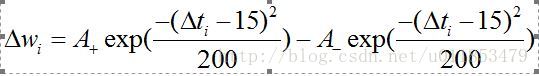
其中, $A+$和$A-$ 表示学习率, 表示突触前脉冲传到突触后脉冲所需的时间。函数关系如图3-2所示。
二相STDP
权值更新规则如公式所示
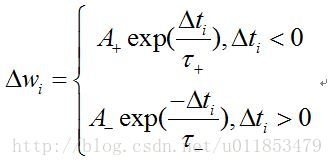
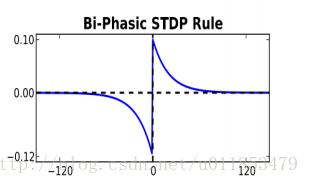
其中, τ+和τ− 用来控制电压下降的速度,被视为时间常数。函数关系如图所示。
2. 脉冲神经网络的监督学习
脉冲神经网络的监督学习是指对于给定的多个输入脉冲序列和多个目标脉冲序列,寻找脉冲神经网络合适的突触权值矩阵,使神经元的输出脉冲序列与对应的目标脉冲序列尽可能接近,即两者的误差评价函数最小。对于脉冲神经网络来说,神经信息以脉冲序列的形式表示,神经元内部状态变量及误差函数不再满足连续可微的性质,构建有效的脉冲神经网络监督学习算法非常困难,同时也是该领域的一个重要的研究方向。
根据监督学习所采用的基本思想不同,可以将现有的监督学习算法分为三类:
- 基于梯度下降的监督学习算法的基本思想是利用神经元目标输出与实际输出之间的误差以及误差反向传播过程,得到梯度下降计算结果作为突触权值调整的参考量,最终减小这种误差。基于梯度下降的监督学习算法是一种数学分析方法,在学习规则的推导过程中,要求神经元模型的状态变量必须是有解析的表达式,主要采用固定阈值的线性神经元模型,如脉冲响应模型(spike response model)和Integrate-and-Fire神经元模型等。
- 基于突触可塑性的监督学习算法的基本思想是利用神经元发放脉冲序列的时间相关性所引起的突触可塑性机制,设计神经元突触权值调整的学习规则,这是一种具有生物可解释性的监督学习。
- 基于脉冲序列卷积的监督学习算法通过脉冲序列内积的差异构造脉冲神经网络的监督学习算法,突触权值的调整依赖于特定核函数的卷积计算,可实现脉冲序列时空模式的学习。
也可以划分为on-line和off-line两类:
- Off-line的方法主要是先训练ANN网络,然后再将连边权重等训练所得参数以及各种超参数固化到SNN网络中。这种方法虽然效果较好,但是很显然丢掉了SNN本身仿生的意义。
- On-line的方法则是将目光聚焦在神经元模型的膜电位上。 脉冲信号是不可求导的,那么现有的众多基于梯度的优化方法也就没法直接应用于SNN。但是与网络中传播的信号不同,神经元的膜电位在很多情况下都是连续可导的,而且前后两个神经元的膜电位变化状况也能反应它们之间传递的脉冲信号。所以很多研究也就集中在使用膜电位制造可导信号上。除此之外,on-line的另一类方法则是关注了脉冲信号累积的效果,同样可以产生类似于连续模拟信号的可导信号。这两类on-line学习方式虽然在传统任务上与off-line方式还有一点差距,但是在动作信号、动画信号甚至文字的识别上展现了强大的能力,在一定程度上实现了将多种任务整合的能力。
除了以上两类优化方式,基于规则的优化方法也逐渐显现出其强大的分类能力。通过对于生物神经网络长期的研究,以及对于ANN和传统图像分类任务的深刻认识,自动化所张铁林老师等人提出了基于稳态调节的SNN优化方法。这种方法中使用了多达五种的SNN突触强度更新规则,同时考虑到了膜电位、侧向抑制、突触短时可塑性、神经元间反向传播信号和生物稳态对于膜电位的作用,最后再用STDP方法将膜电位的变化情况固化到突触连接强度上,实现突触连接的长期可塑变化。相比于STDP,这种方法在一定程度上使用了监督学习方法;相比于其他监督学习方式,这种方法又有着非常充分的生物结构理论背书。这种方法使用简单的三层全连接结构网络就实现了高效的图像分类。但是这种方法同样也有着自己的缺陷,它使用了多种规则进行网络优化,那么需要调节的超参数比其他方法多出许多,使得本来就难以调出较好参数配置的SNN更加难以调参。这三类方法各有优劣,还不能像ANN一样简洁地进行权重更新。
3. 脉冲神经网络的进化方法
进化算法(evolutionary algorithm)是模拟生物进化过程的计算模型,是一类基于自然选择和遗传变异等生物进化机制的全局性概率搜索算法,主要包括遗传算法(genetic algorithm)、进化规划(evolutionary programming)和进化策略(evolutionary strategy)等。虽然这些算法在实现方面具有一些差别,但它们具有一个共同的特点,即都是借助生物进化的思想和原理来解决实际问题的。
将进化算法与脉冲神经网络有机结合起来,研究者开辟了进化脉冲神经网络(evolutionary spiking neural network)的研究领域,以提高对复杂问题的求解能力。进化脉冲神经网络可以作为自适应系统的一种一般性框架,在没有人为干预的情况下系统自适应调整神经元的参数、连接权值、网络结构和学习规则。
SNN学习算法
监督学习基本框架
脉冲神经网络的监督算法目标是实现对脉冲序列中包含的时空模式的信息的学习,脉冲序列的定义:

S(t)对一个Dirac函数进行求和,f代表发放的第f个脉冲,Dirac函数的运算规则:仅当X= 0函数输出1,其他情况函数输出0。
各种脉冲神经网络的监督算法的目标基本一致:对输入脉冲序列Si(t)和期望输出脉冲序列Sd(t),通过监督训练脉冲神经网络,调整权值W,实现神经网络实际输出脉冲序列So(t)与Sd(t)之间的差距尽可能小。

监督训练的一般过程:
(一) 确定编码方式,将样本数据编码为脉冲序列(得到Si(t));
(二) 将脉冲序列输入脉冲神经网络计算得输出脉冲序列So(t);
(三) 将期望脉冲序列和实际输出脉冲序列对比得到误差,并根据误差调整W。
脉冲神经网络的实现难点:
(一) 如何确定编码方式,即如何将样本信息合理地转化为脉冲序列进行训练;
(二) 如何设计脉冲神经元模型,如何模拟脉冲神经网络;
(三) 如何度量实际输出脉冲序列和期望输出脉冲序列误差,即误差函数的合理的定义。
当前对上述难点的解决方案:
(一) 延迟编码、相位编码、Time-to-First.Spike编码、BsA(Bens Spike AlgoIithm)编码等时间编码策略。
(二) LIF,IF,IM,HH模型等;
(三) 误差定义(举例):

脉冲神经网络监督学习算法的关键是构建合适的突触学习规则,其涉及到的方法和技术:
- 神经信息的编码与解码方法
已有的编码方法:神经信息的频率编码、相位编码、Time-to-First-Spike编码、BSA(Bens Spike Algorithm)编码 - 神经元模型与网络模拟策略
根据复杂程度将脉冲神经网络分为:
①具有生物可解释性的生理模型
②具有脉冲生成机制的非线性模型
③具有固定阈值的线性模型 - 脉冲序列的相似性度量方法
基于梯度下降的监督学习算法
SpikeProp算法
适用于多层前馈脉冲神经网络的误差反向传播算法,称为SpikeProp算法,该算法使用了具有解析表达式的脉冲反应模型(SpikeResponse Model,SRM),并为了克服神经元内部状态变量由于脉冲发放而导致的不连续性,限制网络中所有层神经元只能发放一个脉冲。该神经网络的误差函数定义为:

其中,to和td分别表示输出层神经元m的实际脉冲发放时间和目标脉冲发放时间。
监督规则上,对于多突触模型,从突触前神经元i到突触后神经元j的第k个突触权值的梯度计算如下:

其中,y表示无权的突触后电位,根据突触所在层的不同表现为不同的梯度下降学习规则。该算法具有非线性模式分类问题的求解能力。
Multi—SpikeProp算法
对SpikeProp算法改进,应用链式规则推导了输出层和隐含层突触权值的梯度下降学习规则,并将其应用到标准XOR问题,以及更加实际的Fisher Iris和脑电图的分类问题,实验结果表明Multi—SpikeProp算法比SpikeProp算法具有更高的分类准确率。
3.2.3Tempotron算法
Tempotron算法采用监督学习,训练目标是使得实际输出膜电位更符合期望输出膜电位。他认为神经元后突触膜电位(PSPs,Postsynaptic Potentials)是所有与之相连的突触前神经元脉冲输入的**加权和**:

即用核函数K(t)计算所有突触前神经元的脉冲输出贡献加权(w)求和,并加上复位电压得到当前t时间的膜电位,并据此判断该输出神经元是否需要发放脉冲。
因此该算法训练时,根据输出神经元输出的脉冲序列同期望输出脉冲序列的差别,不断调整w权重,权重调整的大小通过核函数计算:

Tempotron采用的神经元模型是Integrate-and-fire模型,成功实现了单脉冲的时空模式分类,但该神经元输出仅有0和1两种输出,此外它无法拓展到多层网络结构。
基于突触可塑性学习算法
Hebb最先提出一个突触可塑性的假说:如果两个神经元同时兴奋,则它们之间的突触得以增强。也就是说,在一个时间窗口内,当突触后神经元的脉冲出现在突触前神经元脉冲之后(也就是上一层发放脉冲之后,下一层相连的神经元跟着发放脉冲),那么就会因此长时程的增强(该突触权重增加),反之则引起长时程抑制(权重削弱)。STDP强调了发放时序不对称的重要性。而且它是一种无监督的学习算法,能够使得突触权值自适应调整。
监督Hebbian学习算法
通过“教师”信号使突触后神经元在目标时间内发放脉冲,“教师”信号可以表示为脉冲发放时间,也可以转换为神经元的突触电流形式。
基于脉冲发放时间的Hebbian学习算法。在每个学习周期,学习过程由3个脉冲决定,包括两个突触前脉冲和1个突触后脉冲。第一个突触前脉冲表示输入信号,第2个突触前脉冲表示突触后神经元的目标脉冲。权值的学习规则可表示为
$$\Delta w=\eta\left(t_o^{f}-t_d^{f}\right)$$
其中,η表示学习率,$t_o^f$ 和$t^f_d$分别表示突触后神经元的实际和目标脉冲时间
通过注入外部输入电流使学习神经元发放特定的目标脉冲序列 I-Learning算法,通过神经元目标和实际输出突触电流的误差进行计算
3.3.2远程监督学习算法(ReSuMe)
STDP和anti-STDP两个过程结合->远程监督方法(Remote Supervised Method, ReSuMe)
应用ReSuMe算法训练脉冲神经网络,突触权值的调整仅依赖于输入输出的脉冲序列和STDP机制,与神经元模型和突出类型无关,因此该算法可用于各种神经元模型。(但仅适用于单层神经网络的学习)
ReSuMe算法的突触权值随时间变化的学习规则为
$$\Delta w_i=\left[S_d(t)-S_o(t)\right]\left[a_d+\int_0^{\infty} a_{di}(s) S_i(t-s) d s\right]$$其中,Si和So分别表示突触前输入脉冲序列和突触后输出脉冲序列, Sd表示目标脉冲序列,对于兴奋性突触,ad参数 取正值,学习窗口 adi(s)表示为STDP规则;对于抑制性突触,adad参数 取负值, adi(s)表示为anti-STDP规则。
应用ReSuMe算法训练脉冲神经网路,突触权值的调整仅依赖于输入输出的脉冲序列和STDP机制,与神经元模型无关,因此该算法可适用于各种神经元模型。后来针对该算法的改进,使得ReSuMe算法可应用到多层前馈脉冲神经网络。
其他STDP监督学习算法
- BCM(Bienenstock-Cooper-Munro)学习规则 + STDP -> SWAT(Synaptic Weight Association Training)算法 脉冲神经网络由输入层、隐含层和输出层构成,网络中隐含层神经元作为频率滤波器,输入和目标输出表示为具有固定频率的脉冲序列。隐含层突触包含兴奋性和抑制性两类。输出层包含一个训练神经元和多个输出神经元。
- 储备池输出层突触延时的监督学习算法
基于脉冲序列卷积的监督学习算法
由于脉冲序列是由神经元发放脉冲时间所构成的离散事件的集合,而离散的数据会导致函数不连续、无法求导数的数学问题,因此引入核函数应用卷积将脉冲序列唯一的转换为一个连续函数:

由上式可得卷积转化后的脉冲序列,可解释为神经元的突触后点位。
卷积的解释:假设当前时间为t,F(a)代表了在a时间是否有脉冲输入,G(t-a)表示了a时间的脉冲对t时间的贡献(影响),因此a时间是否有脉冲对t时间的影响是:
F(a)*G(t-a)
然后对该式积分可得卷积形式的结果,也就是说对每个t,新得到的S(t)的函数结果是对t之前所有发生过脉冲的时间的函数F(A)*G(t-a)的积分,实际意义就在于对之前发生的每次脉冲对当前时间下的影响进行累加,从而计算出当前时间下脉冲大小,于是卷积后,
S(t)就变成了连续的函数。
另外任意两个脉冲序列的内积:

算法:
1. SPAN算法
SPAN(Spike Pattern Association Neuron)算法 应用LIF (Leaky Integrate-and-Fire)神经元模型 主要特点是应用核函数将脉冲序列转换为卷积信号,通过转化后的输入脉冲序列,神经元目标和实际输出脉冲序列,应用Widrow-Hoff规则调整突触权值
2. Precise-Spike-Driven (PSD)算法
PSD算法设计的目的是为处理和记忆时空相关的输入。PSD从传统的Widrow-Hoff规则衍生,作为监督学习规则,利用实际输出脉冲和目标输出脉冲之间的误差修改神经元连接权值:突触权值的调整根据目标输出脉冲与实际输出脉冲的误差来判断,正误差(positive errors)会导致长时程增强,而负误差(negative errors)会导致长时程的抑制。PSD的优势在于在计算上效率较高并且是符合生物学原理的,当编码方式正确时它可以取得很好的识别效果.
每个输入神经元与一个突触后神经元连接;红线描绘了t时间第i个输入神经元发出的电流大小,突触后神经元接收到的PSCs是所有输入神经元发出电流的加权和,它导致了该神经元膜电位的变化。

权值的更新和学习率、期望输出和实际输出之间的差距以及该权值所在突出后电流大小有关
PSD学习规则
PSD从传统的算法中使用WH规则,由于脉冲神经元的输入和输出信号是由脉冲时间描述的,因此不能直接使用WH规则.定义输入、期望输出、实际输出时间序列:

为了解决阶跃函数带来的数学问题,使用卷积的方法,将输入脉冲序列卷积后可得:

输入序列被乘以一个卷积核,原先的WH规则可以被描述为:

现在将yd用Sd(t)代替,yo用So(t)代替,xi用Ipsc代替,于是WH规则可演化为:

在改变的WH规则作用下,在正信号下(Sd = 1 &So = 0)w更新时增大,即刺激了该脉冲神经元在t下的输出;在负信号下(Sd = 0 & So = 1)w更新时减小,即抑制该脉冲神经元在t下的输出。

最终Wi的更新是对所有t时间下Wi(t)更新值的积分:

另外,由于K(t)函数不连续的特征,PSD监督规则下同样无法拓展模型到多层模型。
传统ANN向SNN的转化算法
由于脉冲神经网络的训练算法不太成熟,一些研究者提出将传统的人工神经网络转化为脉冲神经网络,利用较为成熟的人工神经网络训练算法来训练基于人工神经网络的深度神经网络,然后通过触发频率编码将其转化为脉冲神经网络,从而避免了直接训练脉冲神经网络的困难。
ANN转SNN中,我们实际需要的只有ANN中训练的权重,权重又受到ANN中的激活函数,dropout,正则化,池化,权重归一化(如batch Normalization,还有很多类型),输入数据的归一化范围之类的影响。这些技术都会影响到权重值得取值。一般来说,ANN转SNN后,准确度肯定会下降,我们要做的就是尽量将损失减低。而损失的多少直接由权重决定。
CNN转化为SNN
对原始的CNN进行训练,将训练好的权值直接迁移到相似网络结构的SNN。
困难
- CNN中的某一层神经元可能会输出负值,这些负数用SNN表示会比较困难。比如,CNN中的sigmoid函数的输出范围为-1到1,每个卷积层的加权和可能也为负值,在进行颜色空间变换时某个颜色通道也可能取到负值。虽然,SNN可以采用抑制神经元来表示负值,但会成倍地增加所需要的神经元数目,提高计算的复杂度。
- 对于SNN,CNN中神经元的偏置很难表示
- CNN中的Max-pooling层对应到SNN中,需要两层的脉冲神经网络。同样提高了SNN的复杂度。
使用CNN一半需要裁剪
- 保证CNN中的每个神经元的输出值都是正数。在图像预处理层之后,卷积层之前加入abs()绝对值函数,保证卷积层的输入值都是非负的。将神经元的激活函数替换为ReLU函数。一方面可以加快原始CNN的收敛速度,另一方面ReLU函数和LIF神经元的性质比较接近,可以最小化网络转化之后的精度损失。
- 将CNN所有的偏置项都置为0
- 采用空间线性降采样层代替Max-pooling层,一般用average pool。
转化
- SNN的网络结构与裁剪后的CNN相同,单纯地将CNN中的人工神经元替换为脉冲神经元。ANN转SNN有两种类型,是根据SNN采用的模型来进行区别,一种IF模型,另一种LIF模型。LIF相比IF更具有生物真实性。
- 采用IF的SNN,已经可以将损失减到好少(无论应用在全连接网络还是卷积网络),其准确度已经和ANN训练的结果非常接近。这种方法,一般在ANN直接使用relu激活函数进行训练,当然在然后采用一些自定义的权重归一化技术,L1、L2正则化、dropout,对输入数据进行处理等技术,使权重尽量适合于SNN。这种方法已经比较成熟,损失已经非常少,所以人们开始将研究方向转向更具有生物真实性的LIF。
- 采用LIF的SNN,采用这种模型,我们在ANN网络中不在采用relu激活函数,一般是利用LIF模型的响应方程,自己推导出一个与LIF响应方程尽量相似的激活函数。这是这种方法的最难的地方。当前研究一般是将其应用到全连接的网络中。
- 在CNN的卷积层之前增加用于脉冲序列生成的一层网络,对输入的图像数据进行编码,转化为脉冲序列
- 变换决策方式:在某一段时间内,对全连接层输出的脉冲数进行统计,取脉冲数最多的类别作为最终的分类结果
- 将裁减后的CNN训练得到的权值全部迁移到对应的SNN。
最终的转化结果如图所示
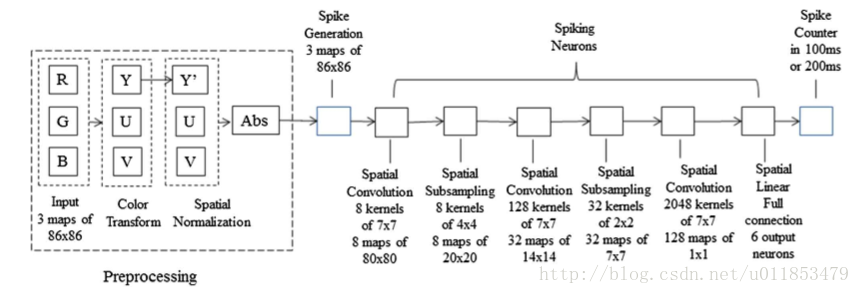
转SNN后性能比较
- 能耗,研究整个网络在一次分类中所产生的总脉冲数,然后利用已知的每个脉冲的能耗,之类的定值计算出总能耗。能耗也可以看成计算量,具有不同网络结构或相同网络结构参数不同(后者主要是针对一些已经训练好的SNN,对数据库进行不同的速率进行脉冲转换)计算各自的产生的脉冲数(计算量)
- 延迟,延迟与SNN模型设置的阈值有很大关系,一般延迟低分类准确性就较低,延迟时间加长分类准确度会上升,这通过我们设置模型的阈值,如果想要高准确度,可以设置高的阈值,这时需要接受较多的脉冲才能激发,因此延迟时间加长,如果想要延迟,就设置低的阈值,这是只要接受几个脉冲就可以激发,延迟低了,但准确性低了。
改进
将ANN转化为SNN造成准确度下降的主要原因是转化后的SNN容易产生过激活(over-activate)和欠激活(under-activate)现象。
- 神经元的输入脉冲不够,导致神经元的膜电压无法超过设定的阈值,造成放电频率过低。
- 神经元的输入脉冲过多,导致ReLU模型在每个采样周期内输出多个脉冲。
- 因为脉冲序列输入是以一定的概率选择的,会导致某些特征一直处于边缘地带或占据了过多的主导地位。
因此,需要对训练得到的权值进行归一化操作。一种是基于模型的归一化操作。考虑所有可能的输入值,选择最大的可能输入值作为归一化因子,这样就保证了最大的可能输入只能产生一个脉冲。另一种是基于数据的归一化操作。输入训练集,找出最大的输入值作为归一化因子。这两种方法原理相同,前者考虑的是最坏情况,后者考虑的是一般情况。
最新进展
SNN相关知识点汇总
1、兴奋性突触与抑制性突触的作用是分别是神经元细胞膜电位的增加与减少。
2、现在流行的人工神经网络所使用的神经元模型(例如ReLU)都是第二代神经元模型。它们主要用于处理模拟数值
3、脉冲神经网络使用的第三代神经元模型,第三代神经元的构建是受生物真实性的启发,它能处理基于脉冲处理的信号
4、脉冲神经网络的两个优势:1、计算效率高。2、具有更强的生物真实性
5、脉冲神经元因其本身具有时间的属性,所以更适合处理有关时序的输入信息
6、脉冲神经元相对复杂,针对输入,它们能提供复杂的非线性映射,从理论上分析,针对一个复杂的任务,一个小型的网络就能解决该任务。
7、神经元模型中的参数τmτm表示的是膜时间常数,它与膜电压的衰减有关,τmτm越大,膜电压Vm(t)Vm(t)衰减的速度越慢
8、从概念和计算的角度来看,与其他尖峰神经元模型相比,LIF模型相对简单,所以采用最广泛。同时LIF模型有个优点就是该模型很容易通过硬件实现,而且运行速度很快。
9、SRM(Spike Response Model)是LIF模型的一个推广,它在神经元动力学中使用了核方法。
10、Hodgkin-Huxley(HH)模型是根据在乌贼身上的大量实验结果所构建的。它是迄今为止最详细和最复杂的神经元模型,然而,该神经元模型的需要很大的计算量,因此该模型不适用于大型网络的仿真。
11、Izhikevich(IM)模型可以通过在神经元动力学方程中设置不同的参数,使神经元具有不同的功能(例如连续激发一系列脉冲或只发射一个脉冲)
12、脉冲神经元本质上是为了处理和产生这种时空脉冲序列。
25、STDP是今年来最常使用的学习算法,它是基于Hebbs理论
26、Tempotron rule 算法只能学习神经元是否产生脉冲,不能是神经元发放脉冲的精准时间,所以该算法不能支持输入和输出峰值中使用的相同的编码方案(因为脉冲输出时间没法确定),基于Tempotron的改进型算法PSD,可以学习到神经元产生脉冲的精准时间。
27、SpikeProp rule可以训练神经元在特定时间产生单个脉冲用于进行时空分类。该算法是一种基于梯度的监督学习算法。该算法的主要缺点是它的输出神经元只能发放一个脉冲,不能产生多个脉冲
28、为了解决SpikeProp输出只能发放一个脉冲的问题,提出Chronotron rule、ReSuMe relu,他们的输出可以是多个脉冲。
29、SPAN relu和Chronotron E-learning relu的权重更新都是基于误差梯度。他们之间的误差梯度有所不同。但这这些基于梯度(数学)所设计的学习算法不具备生物真实性。
参考文献
脉冲神经网络汇总:
https://blog.csdn.net/edward_zcl/article/details/90755592
tempotron:
https://blog.csdn.net/sadfassd/article/details/78463893
https://blog.csdn.net/y1187926460/article/details/78419767
https://blog.csdn.net/sadfassd/article/details/78278595
https://www.cnblogs.com/yifdu25/p/8124119.html
脉冲神经网络学习笔记(综述)
https://blog.csdn.net/sadfassd/article/details/78637718
PSD算法:
https://blog.csdn.net/sadfassd/article/details/78463966
脉冲神经网络基础性知识
https://blog.csdn.net/qq_34886403/article/details/82715629
脉冲神经网络:
https://blog.csdn.net/lu_fun/article/details/80221194
https://blog.csdn.net/edward_zcl/article/details/89031904
https://blog.csdn.net/zjccoder/article/details/40148417
https://blog.csdn.net/h__ang/article/details/90513919
https://blog.csdn.net/qq_34886403/article/details/84504483
https://blog.csdn.net/wydbyxr/article/details/83956277
https://baike.baidu.com/item/脉冲神经网络/4452657?fr=aladdin
脉冲神经元模型:
https://blog.csdn.net/u011853479/article/details/61414913
仿生脉冲神经网络--揭开生物智慧之谜:
http://www.spikingnn.net/
脉冲神经网络与小样本学习附PPT:
https://cloud.tencent.com/developer/news/392411
脉冲编码方式: